F.A.Q.
Foire aux questions reprenant les questions les plus posées par la communauté afin de mieux appréhender le périmètre du PNDB en tant qu'infrastructure virtuelle de recherche nationale (MESR) et centre de référence thématique (Recherche Data Gouv) et ce, en complémentarité avec les autres acteurs (et leurs outils/services).
- Comprendre les {méta}données de biodiversité
- Définition des {méta}données
- Contexte et enjeux des {méta}données
- La science ouverte et les principes FAIR
- Quel est l'historique et la date de création du PNDB ?
- Quels sont les objectifs et missions du PNDB ?
- Quels sont les outils et services du PNDB ?
- Quelles technologies utilisées par le PNDB ?
- Le paysage "données de biodiversité"
- Comment s'intègre le PNDB dans le paysage national et international ?
- Quelles différences et complémentarités entre le SIB, le GBIF France et le PNDB ?
- Partager les {méta}données de biodiversité
- Pourquoi partager des {méta}données ?
- Pourquoi standardiser par la métadonnée ?
- Quelles licences utiliser pour partager les {méta}données ?
- Quels types de données sont partagées par le PNDB ?
- Où partager les {méta}données de biodiversité ?
- Quel outil propose le PNDB pour partager et générer des {méta}données ?
- Quel sont les autres outils pour partager et générer des {méta}données ?
- Utiliser les {méta}données de biodiversité
Comprendre les {méta}données de biodiversité
Définition des {méta}données
|
"Les données de recherche sont définies comme des enregistrements factuels utilisés comme sources primaires pour la recherche scientifique, et qui sont généralement acceptés dans la communauté scientifique comme nécessaires pour valider les résultats de la recherche." OCDE, 2007. https://www.oecd.org/sti/inno/38500813.pdf |

|
“Les métadonnées, que l’on peut définir simplement comme « des données sur les données», sont un moyen de nommer les choses et de représenter les données et leurs relations.” Christine L. Borgman, 2020. https://books.openedition.org/oep/14692 |
Contexte et enjeux des {méta}données
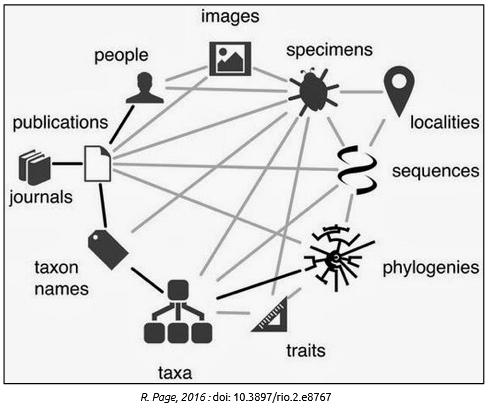
Hétérogénéité dans les types de données (spécimens, données d’observation, Barcoding, cartes satellites, etc.), leur provenance (Entrepôts institutionnels, projets, infrastructures de recherche -observatoires, dispositifs expérimentaux, collections-, tout scientifique désireux de cataloguer des jeux de données) et les standards utilisés (ISO, DarwinCore, EML, etc..)

Une diversité “objets” à relier entre eux et perte d'informations dans le temps
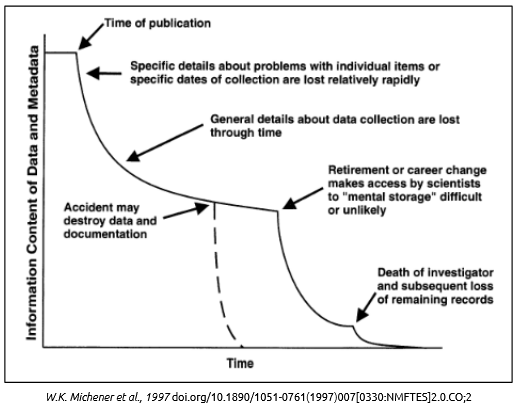
La science ouverte et les principes FAIR

« La France s’engage pour que les résultats de la recherche scientifique soient ouverts à tous, chercheurs, entreprises et citoyens, sans entrave, sans délai, sans paiement. » [lien source]. En France les licences d'utilisation compatibles "licences ouvertes" pour les fichiers de données sont CC-BY 4.0 et Licence Ouverte Etalab 2.0
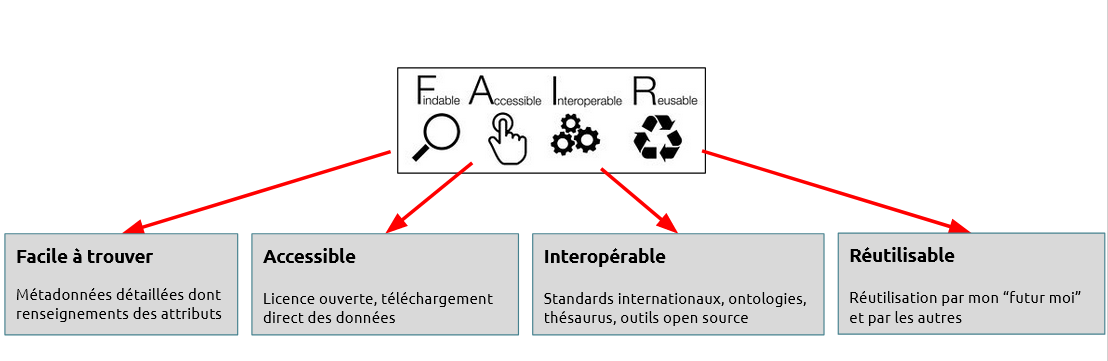
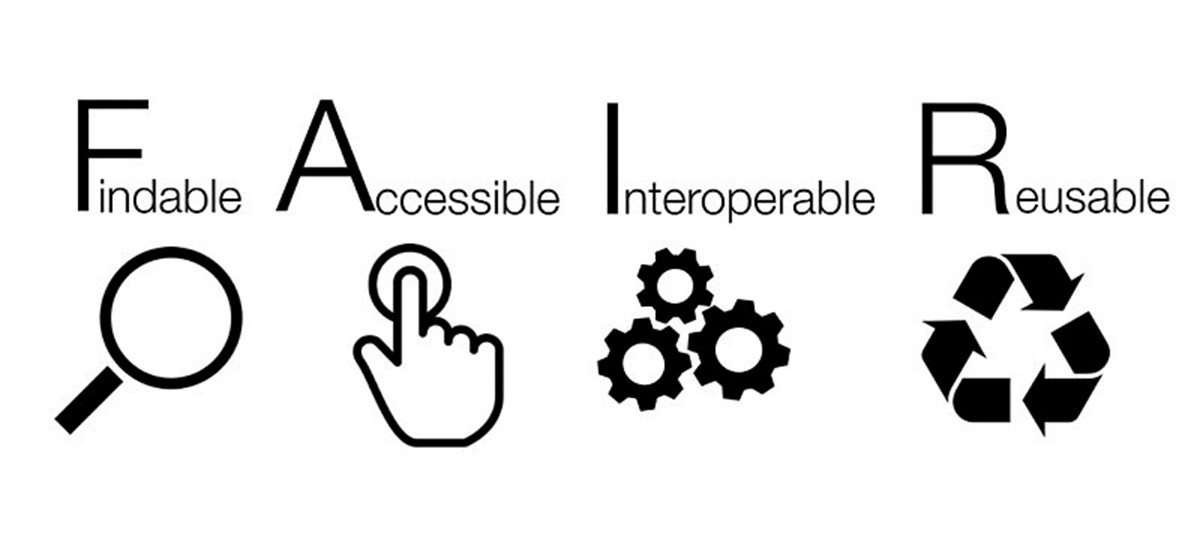
Les principes FAIR utilisés par le PNDB consistent à rendre les données, métadonnées et codes sources faciles à trouver, accessibles, interopérables et réutilisables par l’humain et la machine. (cf. texte fondateur)
Quel est l'historique et la date de création du PNDB ?
Le PNDB est une infrastructure numérique nationale du Système Terre-Environnement créée en 2018 porté par le Muséum National d’Histoire Naturelle, contribuant à la politique de Science ouverte du Ministère de l’enseignement supérieur de la recherche et de l’innovation. Faisant suite à l’initiative ECOSCOPE porté par la Fondation pour la recherche sur la Biodiversité.
Enfin, à l'horizon 2024 le PNDB va intégrer l'infrastructure de recherche intégrative Data Terra.
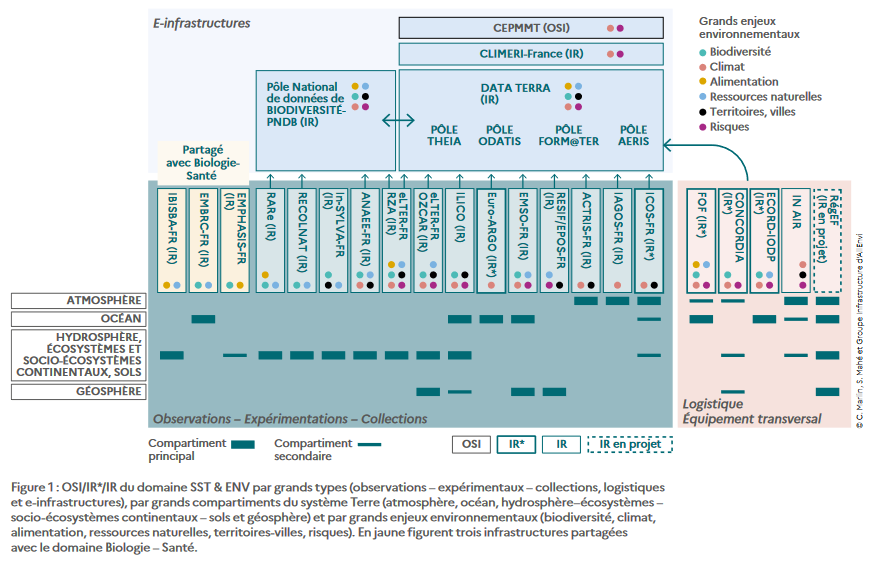
Figure issue de "Ministère de l'Ensignement Supérieur et de la Recherche. 2022. Feuille de route nationale des infrastructures de recherche. disponible en ligne sur https://www.enseignementsup-recherche.gouv.fr/sites/default/files/2022-03/feuille-de-route-nationale-des-infrastructures-de-recherche---2021-v2--17318.pdf"
Quels sont les objectifs et missions du PNDB ?
Le PNDB a pour objectif de mettre à disposition un ensemble cohérent d’outils et de services pour la description, l’accès, la validation, l’analyse et la réutilisation des données de biodiversité, pour les communautés de recherche. Les missions du PNDB s’inscrivent dans une approche FAIR (Facile à trouver, Accessible, Interopérable, Réutilisable), et consistent à :
- fournir un accès aux jeux de données et de métadonnées, à des services associés et à des produits dérivés des analyses ;
- promouvoir l’animation scientifique pour identifier les lacunes en termes d'accompagnement à l'ouverture et à la réutilisation des données, et favoriser les complémentarités entre les communautés productrices et utilisatrices des données. ;
- faciliter le partage des pratiques avec les autres communautés de recherche, favoriser le partage des données et leur réutilisation, s’insérer dans la réflexion de l’infrastructure Data Terra.
- favoriser la cohérence avec les efforts nationaux, européens et internationaux relatifs à l’accès et à l’exploitation des données de recherche sur la biodiversité, à la promotion de produits et services.
De ce fait, les différents objectifs du PNDB sont complémentaires à l’infrastructure Data Terra (que le PNDB va intégrer à l'horizon 2024), notamment dans le cadre du projet GAIA Data qui vise l’étude et la compréhension du système terre, de la biodiversité et du climat dans leur ensemble.
Quels sont les outils et services du PNDB ?
En tant qu'infrastructure de recherche virtuelle et centre de référence thématique du système Terre-Environnement, le PNDB propose aux communuatés de recherche en biodiversité une offre d'outils (pour gérer, produire partager et analyser des {méta}données) et de services adaptés allant de l’élaboration des plans de gestion de données à l’analyse de ces dernières via la production d’indicateurs, en passant par la publication de Data Paper
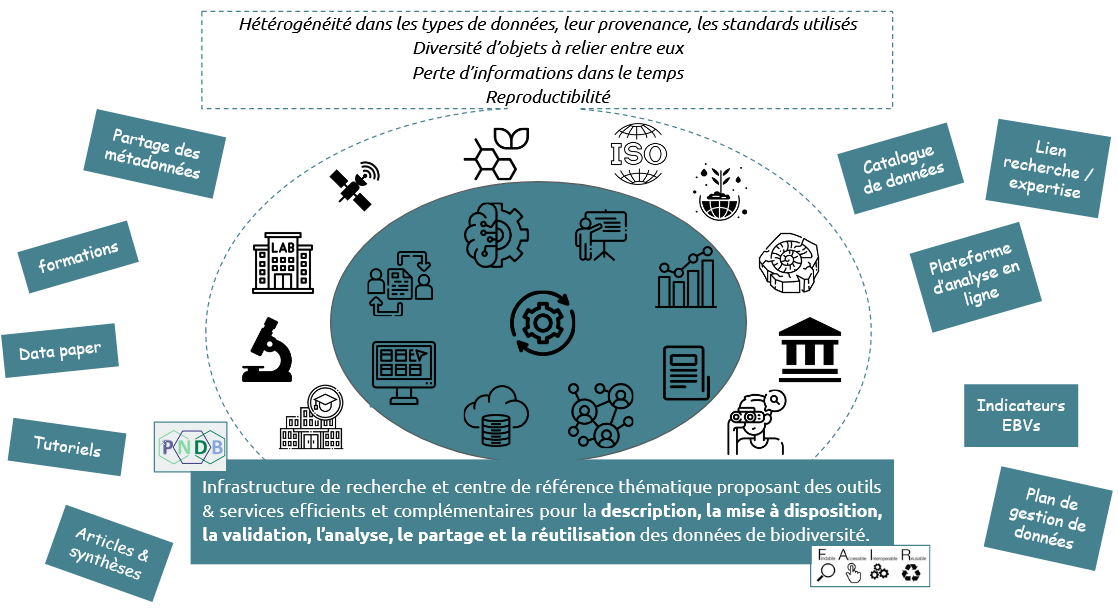
Quelles technologies sont utilisées par le PNDB ?
L’un des principes du PNDB est de capitaliser sur les technologies existantes, qui ont fait leurs preuves et sont utilisées au niveau international.
Par exemple, pour la description fine des métadonnées, le PNDB utilise un standard international, l’Ecological Metadata Language – EML.
De même, notre catalogue de données se base sur Metacat - une plateforme développée dans le cadre du réseau mondial DataOne et maintenu par le premier centre de synthèse mondial en écologie, le « National Centre of Ecological Analysis & Synthesis » aux Etats-Unis.
Enfin notre plateforme d'analayse Galaxy-Ecology se base sur le projet Galaxy initialement développé en biodinformatique

![]()


Le paysage "données de biodiversité"
L’étude du suivi et de l’état de la biodiversité pour les questions de recherche et sa prise en compte dans les politiques publiques françaises nécessitent que les données soient faciles à trouver, accessibles, interopérables et réutilisables (FAIR).
À ce jour, plusieurs systèmes d’information (SI) se structurent actuellement au niveau national et proposent des outils, services et méthodologies pour caractériser, partager, gérer et analyser ces données de biodiversité : le PNDB (pour les données de la recherche) et le SIB (pour les données issues des politiques publiques). Au niveau international on peut également citer le GBIF, Data One, BOLD et le GEO BON. Ces SI présentent une richesse d’acteurs (chercheurs, gestionnaires, citoyens,...), de projets (programmes et dispositifs de recherche - OSU - Zones Ateliers -) et portent sur de nombreuses politiques publiques (Natura 2000, espaces protégés, espèces protégées, …). Tous concourent :
- à l’ouverture des données
- utilisent des cadres analytiques sur les interactions entre la société et l'environnement (DPSIR) et les variables essentielles de biodiversité (EBVs)
- s'intègrent aux bonnes pratiques identifiées dans un cycle de la donnée complet

Figure issue de la restitution des prospectives CNRS-INEE
De plus voici des ressources pouvant aider à la compréhension du paysage :
- Delavaud A. et al. 2014. État des lieux et analyse des paysages des observatoires français de recherche sur la biodiversité. Expertise et synthèse de la Fondation pour la Recherche sur la Biodiversité. Disponible en ligne sur www.fondationbiodiversite.fr/etat-des-lieux-et-analyse-des-paysages-des-observatoires-francais-de-recherche-sur-la-biodiversite/
- Liste des systèmes d'informations liés aux données de biodiversité (intégré à la gouvernance du PNDB - Réseau des réprésentants des systèmes d'informations - RSI)
- Norvez O., Milon T., Pamerlon S., Archambeau A.S., Bouix T., Cheminée O., Le Bras Y., Robert S., Vinet C., 2022. Comprendre, partager et ré-utiliser les données de biodiversité : Note explicative sur la complémentarité des systèmes d’information SIB - SINP - GBIF - PNDB. PatriNat (OFB-MNHN-CNRS-IRD) - Centre d’expertise et de données sur le patrimoine naturel. 23 pages. Etalab- 2.0.https://mnhn.hal.science/mnhn-04296424/document
Comment s'intègre le PNDB dans le paysage national et international ?
Premièrement, la gouvernance du PNDB est composée de 4 instances : Le Comité de pilotage (CoPil), le Conseil Scientifique (CS) et ses Comités d'Experts Scientifiques (CES), le Comité Exécutif (Comex) et le Réseau des responsables des systèmes d'information (RSI).
Le PNDB s’inscrit ainsi dans le paysage des systèmes d’information de biodiversité nationaux et internationaux, le réseau DataOne, le GBIF via son nœud français, etc.). L’une des spécificités du PNDB est de faire le lien entre la recherche et les politiques publiques avec le SIB placé sous la tutelle du ministère de l’environnement. Ceci se matérialise notamment par une représentation conjointe du French BON auprès du GEO BON.
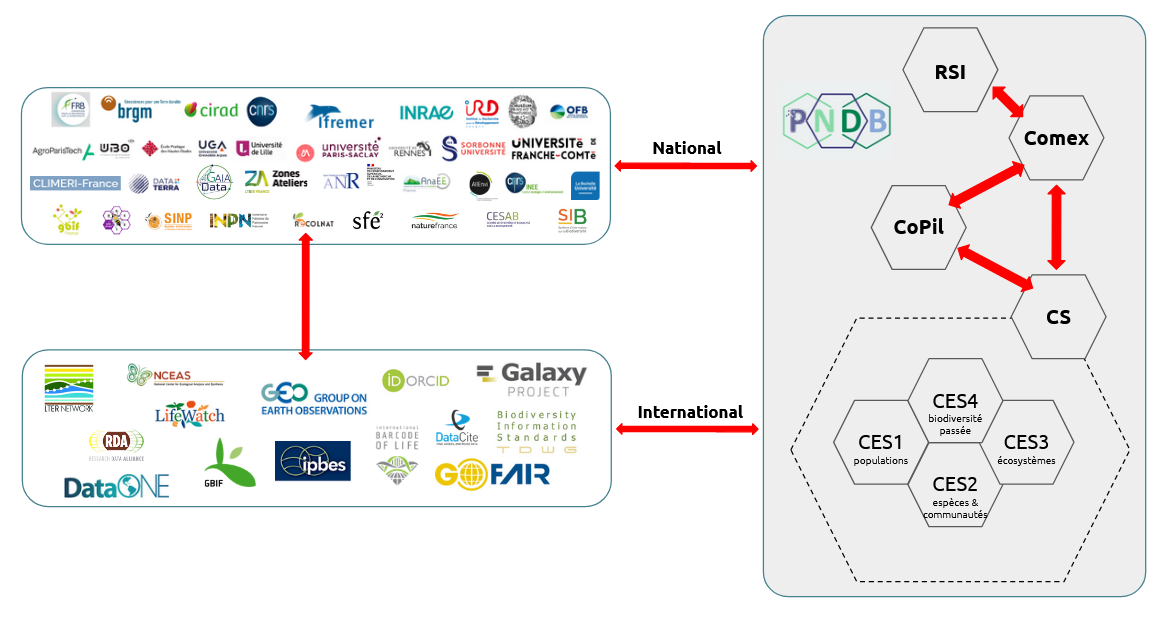
Quelles différences et complémentarités entre le SIB, le GBIF France et le PNDB ?
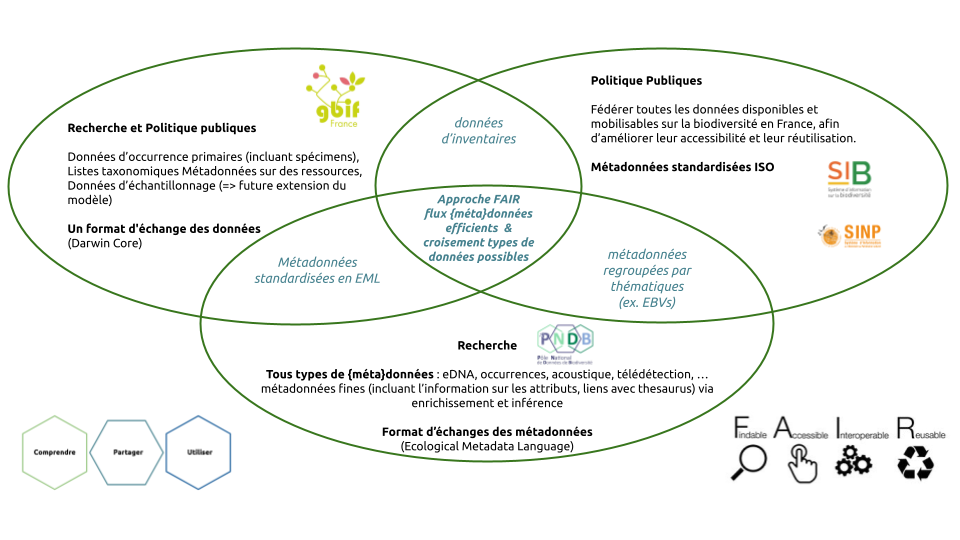
Partager les {méta}données de biodiversité
Pourquoi partager les {méta}données de biodiversité ?
Afin de mieux protéger nos écosystèmes, nous devons mieux les connaître, et pour ce faire, faciliter l’accès et le partage des informations générées et utilisées par les chercheurs pour construire la connaissance scientifique en commençant par l’ouverture la plus généralisée possible des données. Dans les disciplines scientifiques liées à la donnée de biodiversité, la culture du partage de la donnée n’est pas aussi ancrée que dans les disciplines de la biologie moléculaire par exemple.
Pour autant, l’ouverture des données n’est pas suffisante et il est primordial d’y associer des métadonnées détaillées en utilisant des standards largement utilisés à l’international. Dans ce cadre, il apparaît que le domaine de l’écologie possède un avantage face à la multiplicité des standards existants au sein des communautés liées aux technologies *omiques : l’existence d’un langage de métadonnée dédié, modulaire et exhaustif, l’EML.
[voir le projet OpenMetaPaper ] & [voir l'appel à projets DataShare] [Pour aller plus loin autour des data papers : voir la documentation dédiée du service Information Scientifique et Technique du CIRAD]
Pourquoi standardiser par la métadonnée ?
Standardiser par la métadonnée permet :
- la description fine, l’inférence, l’identification et l'interopérabilité des données
- s'intégrer dans l'approche la plus FAIR possible
- une reproductibilité en sciences écologiques.
L’Ecological Metadata Language - EML- est un standard pivot mondialement reconnu et qui a plus de 25 ans de retours d’expériences par les écologues / écoinformaticiens du national center for Ecological Analysis and Synthesis dans le cadre du projet DataONE
La structuration et la FAIRisation des données se font justement via le renseignement de métadonnées au format EML.


Images et textes tirés de M.B. Jones et al., 2006 https://www.annualreviews.org/doi/10.1146/annurev.ecolsys.37.091305.110031
Nota Bene : toutes les {méta}données recherche moissonnées par le PNDB seront remontées au GBIF si ces dernières sont compatibles au format et standard "DarwinCore" (ex. Données d’occurrence primaires (incluant spécimens), Listes taxonomiques Métadonnées sur des ressources, Données d’échantillonnage).
Quelles licences utiliser pour partager les {méta}données ?
Le PNDB met en avant des jeux de données (via les métadonnées) en open access avec une licence Creativ Commons CC-BY 4.0 ou licence Etalab . En France les licences d'utilisation compatibles "licences ouvertes" pour les fichiers de données sont CC-BY 4.0 et Licence Ouverte Etalab 2.0
https://www.ouvrirlascience.fr/plan-national-pour-la-science-ouverte/



Quels types de données sont partagées par le PNDB ?
Les données traitées par le PNDB concernent toutes les dimensions de la biodiversité, dans le but de prendre en compte la biodiversité sur le temps long (depuis les origines de la vie), à toutes les échelles biologiques (de la molécule à l’anthropo-écosystème), et dans toutes ses interactions.
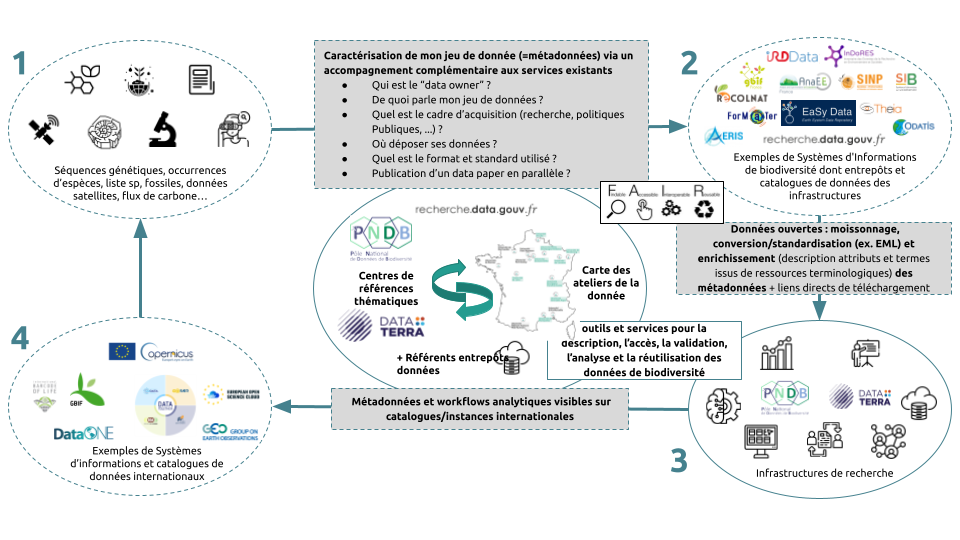
Ces données proviennent essentiellement des systèmes d’informations, entrepôts institutionnels, infrastructures de recherche (observatoires, dispositifs expérimentaux, collections..), mais également des données d’expertise qui proviennent elles du système d’information sur la Biodiversité – SIB – fédérant les données des politiques publiques. Le portail doit permettre aux communautés scientifiques françaises de partager leurs données, qu’elles concernent des échantillonnages pratiqués sur le territoire national ou à l’étranger.
Le but du PNDB est de donner accès aux données brutes (fichiers tabulés, tableurs, média, extraction de bases de données, bases de données, …) utilisés par les scientifiques pour leurs analyses via un accès à un catalogue de métadonnées.
Différents formats sont pris en compte (fichiers de tableurs, fichiers textes csv, ..), fichiers SIG raster et vecteurs, fichiers média (images, sons, …), vues de bases de données, …
Enfin, toutes les données (nommées entités de données en EML) utilisées en entrée et sorties d’analyses sont ainsi potentiellement concernées, mais également les logiciels d’analyse (outils / scripts), et les protocoles.
Nota Bene : toutes les {méta}données recherche moissonnées par le PNDB seront remontées au GBIF si ces dernières sont compatibles au format et standard "DarwinCore" (ex. Données d’occurrence primaires (incluant spécimens), Listes taxonomiques Métadonnées sur des ressources, Données d’échantillonnage).
Où partager les {méta}données de biodiversité ?
Un important travail est en cours de réalisation pour illustrer les bonnes pratiques de partage des {méta}données (choisir le bon entrepôts de données d données, qui contacter, les outils existants pour décrire et partager les données, ...), et sera prochainement disponible, dans l'attente de dernier, voici ci-dessous quelques éléments d'informations :
Ainsi, le PNDB n’a pas pour mission de jouer le rôle d’entrepôt de données. Le stockage de vos données doit se faire dans les entrepôts de données de votre institution ou entrepôt institutionnel. nous pouvons notamment citer les entrepôts INRORES du CNRS-INEE , dataverse de l'IRD , dataverse du CIRAD, ... (cf. liste des entrepôts et/ou SI associés à la biodiversité).
De plus Recherche Data Gouv propose un logigramme pour savoir "où déposer ses données?" voir le logigramme
Quel outil propose le PNDB pour partager et générer des {méta}données ?
Nota Bene : MetaShARK (pour Metadata Shiny Application for Resources and Knowledge) est un outil R&D financé par le Fond National pour la Science Ouverte, dans le cadre du projet OpenMetaPaper . Cet outil n'est pas disponible car actuellement en crash test interne
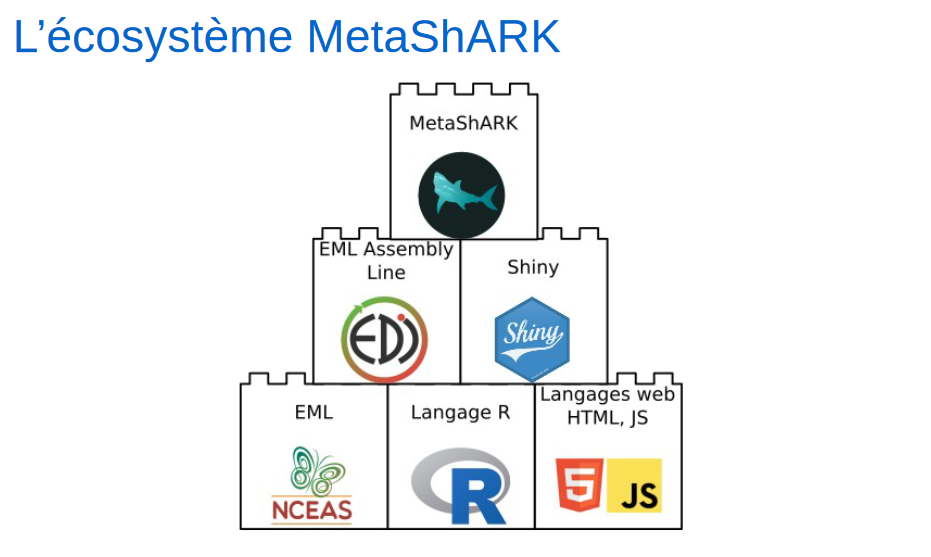
Exemple de génération de métadonnées EML à partir d'ensembles de données via MetaShARK
Quel sont les autres outils pour partager et générer des {méta}données ?
Le secrétariat du GBIF a développé l’IPT comme une plate-forme logicielle pour faciliter la publication des données sur le web, grâce au réseau GBIF. L’IPT est une web application Java qui gère différents types de données :
- Données d’occurrence primaires (incluant spécimens)
- Listes taxonomiques
- Métadonnées sur des ressources
- Données d’échantillonnage
standards actuels : DarwinCore pour données, EML pour métadonnée
Le GBIF France peut vous accompagner dans l apubication de ces trois types de données et/ou dans l'accompagnement pour la publication d'un data paper.
![]()
Nota Bene : toutes les {méta}données recherche moissonnées par le PNDB seront remontées au GBIF si ces dernières sont compatibles au format et standard "DarwinCore" (ex. Données d’occurrence primaires (incluant spécimens), Listes taxonomiques Métadonnées sur des ressources, Données d’échantillonnage).
Utiliser les {méta}données de biodiversité
Pourquoi réutiliser des {méta}données ?
Afin de mieux protéger nos écosystèmes, nous devons mieux les connaître, et pour ce faire, faciliter l’accès et le partage des informations générées et utilisées par les chercheurs. Mises en commun, ces données existantes peuvent alimenter des problématiques inédites, faire avancer significativement les fronts de connaissances et fournir des recommandations pour les décideurs.
[voir le CESAB pour les méta-analyses]
Quelles licences pour réutliser des {méta}données ?
Le PNDB met en avant des jeux de données (via les métadonnées) en open access avec une licence Creativ Commons CC-BY 4.0 ou licence Etalab (les 2 licences open access recommandées en science en France). Vous pouvez donc réulitiser ces jeux de données en citant la source de ces derniers via un identificant unique (UUID, DOI, etc..)
Où trouver des jeux de données ?
Le PNDB propose un catalogue avec un lien de téléchargement direct des données (sans être un “lieu de stockage”)
- via une description fine des métadonnées intégrées
- moissonnage des métadonnées avec d’autres SI et entrepôts institutionnels
- possibilité de proposer des sous-portails pour un projet (Challenge IA-Biodiv), une thématique (ex. les les variables essentielles de biodiversité - EBVs)
- permet d'obtenir un metadat assessment report (sur 51 critères FAIR)
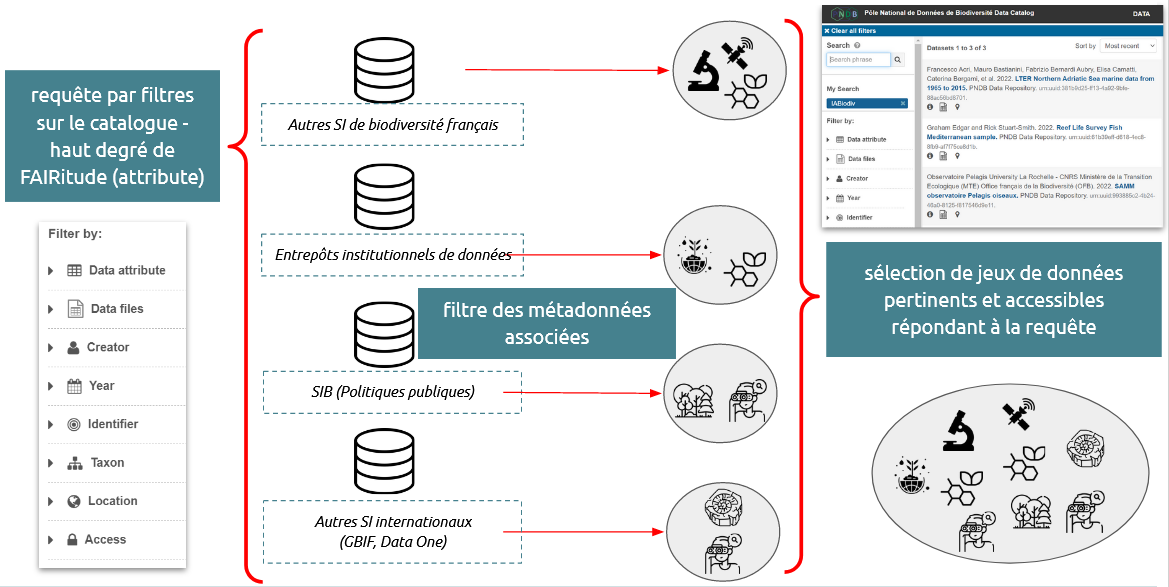
|
Les fonctions du catalogue PNDB
|

Vous pouvez aussi chercher dans chaques systèmes d'informations et/ou entrepôts institutionnels/thématiques des jeux de données (voir liste)
Comment analyser mes données ?
Il existe de nombreuses ressources (logiciels, langage de programmation, packages, ...) pour analyser des données de biodiversité, mais on peut notamment citer la plateforme d'analyse en ligne Galaxy-Ecology développée par l'équipe du PNDB (et qui se base sur Galaxy project un des plus grands projets scientifiques international collaboratif open source en science). De plus, l'équipe PNDB intégre également des outils au sein de la plateforme d'analyse en ligne Galaxy-Ecology afin de faciliter leur accès au plus grand nombre et via une interface collaborative facilitant le partage, la transparence et la réutilisation des outils de visualisation et analyse de données en écologie.
Galaxy-Ecology permet :
- le nettoyage des données

- la visualisation et les tendances
- la personnalisation et/ou l’utilisation de cadre analytiques robustes et reproductibles
- la production d’indicateurs
|
Vous débutez sous Galaxy ou voulez juste voir comment cela fonctionne ? Vous trouverez des supports de formations en vous rendant sur le site du « Galaxy Training Network » dont des tutoriels introductifs à Galaxy et d’autres dédiés Galaxy-E. |
De plus le Cesab – Centre de synthèse et d’analyse sur la biodiversité (Fondation pour la Recherche sur la Biodiversité) propose de nombreuses ressources pour gérer, structurer et analyser vos données de biodiversité via leur la page GitHub du CESAB
